The above model may be easily extended to include some non-deterministic intensity characteristics for the shapes. For instance, typical shapes are characterised not only by a mean intensity and a spatially-linear intensity gradient, but also by a distribution of intensities about this deterministic intensity model. This distribution can be characterised empirically and used in the similarity model, as done in [,]. Alternatively, the distribution can be approximated by a Gaussian and these variance properties inserted into the above model.
Consider that each shape (![]() ) is associated with a Gaussian noise
process (of length
) is associated with a Gaussian noise
process (of length ![]() ),
), ![]() , where
, where
![]() . The model of image formation is now
. The model of image formation is now
![]() , where
, where ![]() is an
is an ![]() by
by ![]() weighting matrix given by
weighting matrix given by
![]() - i.e. a
diagonal matrix where the diagonal elements are taken from the vector
- i.e. a
diagonal matrix where the diagonal elements are taken from the vector
![]() . This weighting is such that the noise process
. This weighting is such that the noise process ![]() will only affect voxels that overlap
will only affect voxels that overlap ![]() and will not affect other
voxels.
and will not affect other
voxels.
The random component of this model
is
![]() and is a multivariate
Gaussian with covariance of
and is a multivariate
Gaussian with covariance of
![]() . As a consequence the likelihood
becomes
. As a consequence the likelihood
becomes
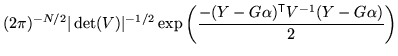 |
|||
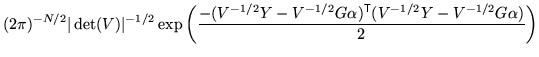 |
The posterior for this new model now also depends upon the parameters,
![]() (or
(or
![]() ) which can be either treated
as known parameters, or marginalised numerically. Their effect on the
projection matrices and determinants is such that analytical
marginalisation is intractable. Also, it is often more convenient to
subsume the measurement noise,
) which can be either treated
as known parameters, or marginalised numerically. Their effect on the
projection matrices and determinants is such that analytical
marginalisation is intractable. Also, it is often more convenient to
subsume the measurement noise, ![]() , with the new random
processes,
, with the new random
processes, ![]() , in order to simplify the model and
marginalisation. This simply has the effect of changing the values of
, in order to simplify the model and
marginalisation. This simply has the effect of changing the values of
![]() that will be used (or integrated over) in practice, since
all of these processes are considered independent.
that will be used (or integrated over) in practice, since
all of these processes are considered independent.