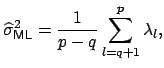Throughout the remainder of this paper, we are going to keep the parameter
![]() fixed at its ML estimate:
fixed at its ML estimate:
Without loss of
generality we will also assume that the sources have unit variance for we can
freely exchange arbitrary scaling factors between the source signals
and the associated columns of the mixing matrix
![]() .
.
If the noise covariance
![]()
![]() was known we can
use
its Cholesky decomposition
was known we can
use
its Cholesky decomposition
![]()
![]()
![]()
![]()
![]()
![]() to rewrite equation
2:
to rewrite equation
2:
Noise and signal are assumed to be uncorrelated and therefore
Estimating the mixing matrix
![]() thus reduces to
identifying the square matrix
thus reduces to
identifying the square matrix
![]() after whitening the data with respect to the
noise covariance
after whitening the data with respect to the
noise covariance
![]()
![]() and projecting the temporally whitened observations
onto the space spanned by the
and projecting the temporally whitened observations
onto the space spanned by the ![]() eigenvectors of
eigenvectors of
![]()
![]() with largest
eigenvalues.
From
with largest
eigenvalues.
From
![]() , the maximum likelihood source estimates are
obtained using generalised least squares:
, the maximum likelihood source estimates are
obtained using generalised least squares:
The maximum likelihood solutions given in equations 5-7 give important insight into the methodology.
Firstly, in the case where ![]() and
and
![]()
![]() are known, the
maximum likelihood solution for
are known, the
maximum likelihood solution for
![]() is contained in the principal
eigenspace of
is contained in the principal
eigenspace of
![]()
![]() of dimension
of dimension ![]() , i.e. the span of the first
, i.e. the span of the first ![]() eigenvectors equals the span of the unknown mixing matrix
eigenvectors equals the span of the unknown mixing matrix
![]() . Projecting the
data onto the principal eigenvectors is not just a convenient technique to deal
with the high dimensionality in FMRI data but is part of the maximum likelihood
solution under the sum of square loss. Even if estimation techniques are
employed that do not use an initial PCA step as part of the ICA estimation, the
final solution under this model is necessarily contained in the principal
subspace. Secondly, combining these results with the uniqueness results stated
earlier we see that only in the case where the analysis is performed in
the appropriate lower-dimensional subspace of dimension
. Projecting the
data onto the principal eigenvectors is not just a convenient technique to deal
with the high dimensionality in FMRI data but is part of the maximum likelihood
solution under the sum of square loss. Even if estimation techniques are
employed that do not use an initial PCA step as part of the ICA estimation, the
final solution under this model is necessarily contained in the principal
subspace. Secondly, combining these results with the uniqueness results stated
earlier we see that only in the case where the analysis is performed in
the appropriate lower-dimensional subspace of dimension ![]() are the source
processes uniquely identifiable.
Finally, equations 5-7 imply that the standard
noise-free ICA approach with dimensionality reduction using PCA implicitly
operates under an isotropic noise model.
are the source
processes uniquely identifiable.
Finally, equations 5-7 imply that the standard
noise-free ICA approach with dimensionality reduction using PCA implicitly
operates under an isotropic noise model.
The remainder of this paper illustrates that by making this specific noise model explicit in the modelling and estimation stages, we can address important questions of model order selection, estimation and inference in a consistent way.
An immediate consequence of the fact that we are operating under an isotropic
noise model is that as an initial pre-processing step we will modify the
original data time courses to be normalised to zero mean and unit variance. This
appears to be a sensible step in that on the one hand we know that the voxel-wise standard deviation of resting state data varies significantly over the brain but on the other hand,
all voxels' time courses are assumed to be generated from the same noise process.
This variance-normalisation pre-conditions the data under the 'null
hypotheses' of purely Gaussian noise, i.e. in the absence of any signal: the
data matrix
![]() is identical up to second order statistics to a simple set of
realisations from a
is identical up to second order statistics to a simple set of
realisations from a
![]() noise process. Any signal
component contained in
noise process. Any signal
component contained in
![]() will have to reveal itself via its deviation from
Gaussianity. This will turn out to be of prime importance both for the
estimation of the number of sources and the final inferential steps.
will have to reveal itself via its deviation from
Gaussianity. This will turn out to be of prime importance both for the
estimation of the number of sources and the final inferential steps.
After a voxel-wise normalisation of variance, two voxels with comparable
noise level that are modulated by the same signal time course,
![]()
![]() say, but
by different amounts will have the same regression coefficient upon regression
against
say, but
by different amounts will have the same regression coefficient upon regression
against
![]()
![]() . The difference in the original amount of modulation is therefore
contained in the standard deviation of the residual noise. Forming voxel-wise
. The difference in the original amount of modulation is therefore
contained in the standard deviation of the residual noise. Forming voxel-wise
![]() statistics, i.e. dividing the PICA maps by the estimated standard deviation
of
statistics, i.e. dividing the PICA maps by the estimated standard deviation
of
![]() , thus is invariant under the initial variance-normalisation.
, thus is invariant under the initial variance-normalisation.