

Next: Discussion
Up: Results
Previous: Autoregressive model and Nonparametric
We have established that without any spatial regularisation of the autocorrelation
estimate, the single taper Tukey with 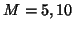 perform best.
We now want to explore the additional benefits, if any, of using the
SUSAN spatial smoothing of the raw autocorrelation estimate before the Tukey
tapering is applied and also to establish how much smoothing is of benefit.
Spatial autocorrelation of the
perform best.
We now want to explore the additional benefits, if any, of using the
SUSAN spatial smoothing of the raw autocorrelation estimate before the Tukey
tapering is applied and also to establish how much smoothing is of benefit.
Spatial autocorrelation of the 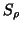 map suggests that the autocorrelation
is only correlated over a short range. The voxel dimensions for the 6 datasets
are
map suggests that the autocorrelation
is only correlated over a short range. The voxel dimensions for the 6 datasets
are
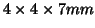 and hence we consider SUSAN filtering with
and hence we consider SUSAN filtering with
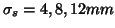 .
.
Although the single taper Tukey performed better with 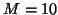 ,
because we are now
regularising spatially,
it turns out to be better to allow more flexibility (i.e.
less smoothing) of the spectral density by choosing
a Tukey taper with
,
because we are now
regularising spatially,
it turns out to be better to allow more flexibility (i.e.
less smoothing) of the spectral density by choosing
a Tukey taper with 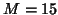 . Figures 16 (TR=3 secs) and
17(b) (TR=1.5 secs) show the results of the
different amounts of spatial smoothing. A
. Figures 16 (TR=3 secs) and
17(b) (TR=1.5 secs) show the results of the
different amounts of spatial smoothing. A 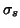 of
of 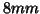 performs
best and shows improvement over performing no spatial smoothing for the TR=3 secs data and performs similarly for the TR=1.5 secs data.
performs
best and shows improvement over performing no spatial smoothing for the TR=3 secs data and performs similarly for the TR=1.5 secs data.
Figure 13:
Comparison of Tukey autocorrelation estimation
for different values of 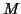 via
log probability plots comparing theoretical
via
log probability plots comparing theoretical 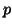 against
null distribution
against
null distribution 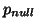 obtained from six different null datasets
using TR=3 secs for (a) a
boxcar design convolved with a gamma HRF, and (b) a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening.
The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
obtained from six different null datasets
using TR=3 secs for (a) a
boxcar design convolved with a gamma HRF, and (b) a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening.
The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
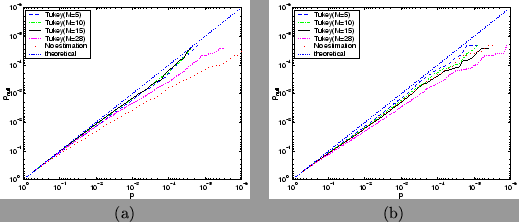 |
Figure 14:
Comparison of Multitapering autocorrelation estimation
for different values of  via
log probability plots comparing theoretical against
null distribution obtained from six different null datasets using TR=3 secs for (a) a
boxcar design convolved with a gamma HRF, and (b) a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening.
The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
via
log probability plots comparing theoretical against
null distribution obtained from six different null datasets using TR=3 secs for (a) a
boxcar design convolved with a gamma HRF, and (b) a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening.
The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
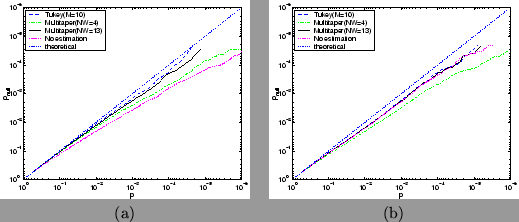 |
Figure 15:
Comparison of the different autocorrelation estimation
techniques via
log probability plots comparing theoretical against
null distribution obtained from six different null datasets using TR=3 secs for (a) a
boxcar design convolved with a gamma HRF, and (b) a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening.
The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
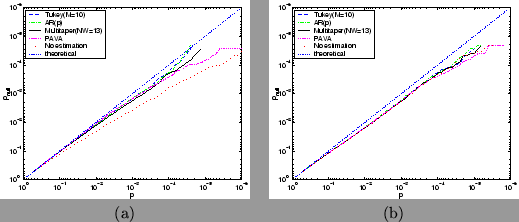 |
Figure 16:
Comparison of different amounts of spatial smoothing of the
raw autocorrelation estimate prior to using Tukey tapering with , via
log probability plots comparing theoretical against
null distribution obtained from six different null datasets using TR=3 secs for (a)
a boxcar design convolved with a gamma HRF, and (b) a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening.
The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
MS is the mask-size used in the SUSAN smoothing and corresponds to .
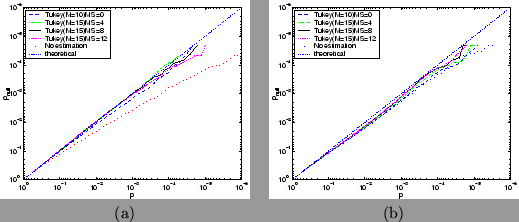 |
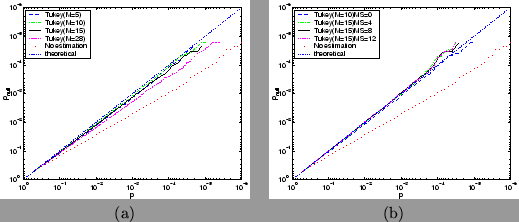
Figure 17:
(a) Comparison of Tukey autocorrelation estimation
for different values of , and (b) Comparison of different amounts
of spatial smoothing of the raw autocorrelation estimate prior to using Tukey
tapering with , for data taken with TR=1.5 secs.
The comparison is made via
log probability plots comparing theoretical against
null distribution obtained from nine different null
datasets with a
stochastic single-event design convolved with a gamma HRF. All are calculated
using prewhitening. The straight dotted line shows the result for
what would be a perfect match between theoretical and null distribution.
MS is the mask-size used in the SUSAN smoothing and corresponds to .
 |
Next: Discussion
Up: Results
Previous: Autoregressive model and Nonparametric
Mark Woolrich
2001-07-16