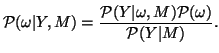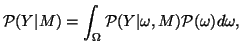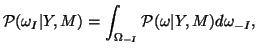The second approach is to associate a probability density function with the parameters. In the Bayesian framework, this distribution is called the posterior distribution on the parameters given the data
Unfortunately, calculating this pdf is seldom straightforward. The denominator in equation 2 is
One solution to this problem is to draw samples in parameter space from the joint posterior distribution, implicitly performing the integrals numerically. For example, we may repetitively choose random sets of parameter values and choose to accept or reject these samples according to a criterion based on the value of the numerator in equation 2. It can be shown (e.g [12]) that a correct choice of this criterion will result in the accepted samples being distributed according to the joint posterior pdf (equation 2). Schemes such as this are rejection sampling and importance sampling which generate independent samples from the posterior. Any marginal distributions may then be generated by examining the samples from only the parameters of interest. However, these kinds of sampling schemes tend to be painfully slow, particularly in high dimensional parameter spaces, as samples are proposed at random, and thus each has a very small chance of being accepted.
Markov Chain MonteCarlo (MCMC) (e.g. [12,13]) is a sampling technique which addresses this problem by proposing samples preferentially in areas of high probability. Samples drawn from the posterior are no longer independent of one another, but the high probability of accepting samples, allows for many samples to be drawn and, in many cases, for the posterior pdf to be built in a relatively short period of time.