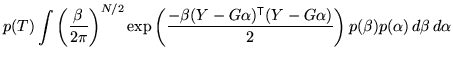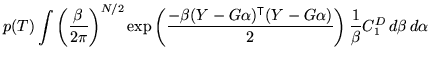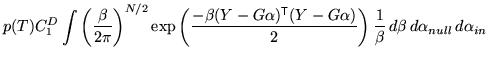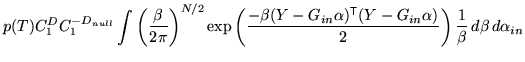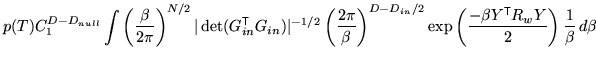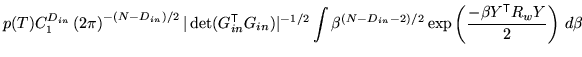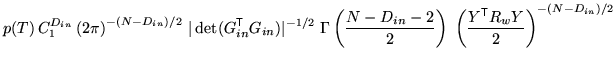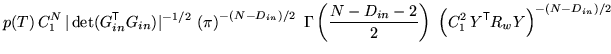Initially consider the case of a flat prior on ![]() . In this case
let the range of each individual
. In this case
let the range of each individual ![]() be 0 to
be 0 to
![]() such that, then
such that, then
![]() . When included,
. When included, ![]() parameters associated with linear intensity gradients have the
appropriate columns of
parameters associated with linear intensity gradients have the
appropriate columns of ![]() scaled so that the range of
scaled so that the range of ![]() is
is
![]() to
to
![]() , and
, and
![]() is still
true. Note that
is still
true. Note that ![]() is a constant for all
is a constant for all ![]() , and represents
the inverse intensity range.
, and represents
the inverse intensity range.
To start with, take the case where there are no uninteresting,
degenerate or partial volume parameters. Note that there may be null
parameters. In these conditions, the posterior can be simply
calculated using the integrals in appendix A, giving
Note that ![]() and
and ![]() both depend on the transformation
both depend on the transformation ![]() . In
fact, the dependence on
. In
fact, the dependence on ![]() is a form of normalisation for the
number of degrees of freedom in the model. Also note that
is a form of normalisation for the
number of degrees of freedom in the model. Also note that
![]() in all cases so that
in all cases so that
![]() and that increasing the normalised
residuals
and that increasing the normalised
residuals
![]() causes the posterior probability to
decrease, as desired.
causes the posterior probability to
decrease, as desired.
The above integrations use the approximation that
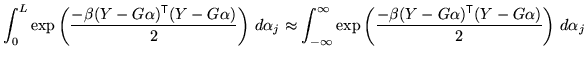
When these conditions are not true, the above approximation breaks
down and the complimentary error function
![]() terms, as shown in
equation 14 in appendix A, must be
included. This is true for pure partial volume parameters, and will
be treated in section 3.2.2 which will be the last
parameters to be integrated over.
terms, as shown in
equation 14 in appendix A, must be
included. This is true for pure partial volume parameters, and will
be treated in section 3.2.2 which will be the last
parameters to be integrated over.