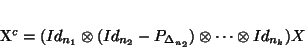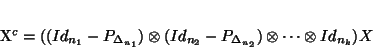Preprocessing such as centring and/or scaling enables the analysis to focused on a chosen
variation of interest. It can sometimes be a solution to the problem of subject effect and
outlier effects (effects occurring in the pharmaco-EEG data, see [11]). Centring
and/or reducing variables before analysis is common in multivariate analysis such as PCA. Usually
centring is seen as a simple statistical model focussing on residuals from a regression model and
has connections with algebraic and geometrical properties, such as being the projection onto the
orthogonal of the subspace generated by the regressors. With this interpretation and leaving,
aside the statistical sampling who generated the data, it is possible in fact to centre and/or
reduce on any mode or combined mode of our multi-entries data.
Remembering the structure of our data described at the beginning of section 4, the
question is now ``what are we looking for?" which should guide our decisions with respect to
centring/reducing. The question could be formulated as ``what are we not interested in?". At first
sight the answer to this one is subject differences, but also the interactions of
subject and the other ``dimensions". If the data is firstly whole centred, centring and removing
effects (as in ANOVA) are linked. To understand this point consider the problem in two modes with
whole centred, i.e. :
is called in [20] centring across the first mode, and is equivalent in
ANOVA language to remove the effect of the second mode. This is the reason why one usually centres
across the mode of interest. It is possible to give an algebraic expression to this
transformation : with a tensor of order k when centring across say the second mode,
is transformed to :
(13)
where
is the orthogonal projector onto the vector
of length , and is the identity operator onto
.
The expression (13) is using the tensor product of linear operators (see also next
section) which is isomorphic to the Kronecker product of their matrices (for any given basis
choices). Performing a double centring say across the first mode and across the second mode can
be written :
(14)
It easy to show that it is equivalent to perform the two single centring one after the other. Care
is needed in multiple centring and /or reducing involving centring across slices (2 modes
varying) as well, as one can cancel or slightly modify the other centring. This is because doing
successively mode centring and slice centring may break the tensorial structure. A
simple example involving only slice centring and showing a broken tensorial structure would be to
centre across slice [mode 1 and mode 2] and then across slice [mode 2 and mode 3]! For such
situations, iterative centring and scaling can be also be thought as for the PARAFAC method in
[20] but this preprocessing algorithm may then become a true modelling part of
the analysis for which interpretation and analysis of the explained part () may be
needed.
For EEG data it is possible to have this ANOVA like approach for all the entries (at least when
looking at absolute energies) as one can consider the data as a measure of the EEG amplitude on
the subjects at the repeated conditions : electrodes, frequency bands, time, and doses. Note the
structure of the data ensures a balanced design and so orthogonality of factors for the ANOVA. The
problem in using this ANOVA approach is that if distributions are not normal with small variances,
a factor effect measured with means will not be completely removed, i.e. the
variation left may be still important. Others structures than the one giving the mean model can
be considered for an entry , the formula (14) can be reformulated replacing the
model by the appropriate (a ``design" describing the structure usually
including ) .
Figure 4:
PTA-modes of all bands (absolute energies) for verum versus placebo
versus first baseline: Principal tensor (a) original data, (b) subjects scaled to unit,
(c) globally-modified data (d) levels-modified data; (preprocessing b, c, and d
explained in the text).
Scaling (or reducing) variables is commonly used when the variable units are not the same. For EEG
measurements subjects can be thought to have their own units. Global subject
differences in location and in variability are not of interest for our purpose, so reducing their
variability to the same unit would also improve the analysis. Unfortunately centring or removing
effects does not insure vanishing outliers, but sometimes successfully diminishes the variability
induced by their presence so that it appears in a less important (lower singular value) Principal
Tensor. A complete illustration of this fact is shown in [12]. On
fig.4 a comparison of the first principal tensor obtained from the data
[dose*subject lead time band] with different preprocessing is
shown .
To modify the data using the ANOVA approach it is possible to remove interactions of each factor
(mode) with subjects globally or by levels of other factors. For example on the
subject scaled data was removed : subject.dose by time and band, subject.band by
time and dose, subject.time by band dose, and, subject.electrode by band dose.
Notice the first interactions are then computed on the electrode units, and the last one is
computed on time units. This way of proceeding can make more sense than computing these
interactions globally on the rest of the units, and actually provided better results. A
verification was done in comparing full ANOVA models (the subject factor being the
experimental units) respectively on the subject scaled data, the globally-modified
data (interactions and main subject effect removed), the levels-modified data (as before
but by levels). We obtained as explained respectively : , , and , which means
some unwanted variation in the data were successfully removed. Next:Analysing summaries and PTAIV-kmodes Up:tr00dl2 Previous:A first analysis
Didier Leibovici
2001-09-04
![\scalebox{0.7}[0.7]{\includegraphics[width=3.5cm]{sy1111.ps}
\includegraphics[width=5cm]{sz1111.ps}
\includegraphics[width=5cm]{sxt1111.ps}}](img151.gif) [Subject scaled data]
[Subject scaled data]
![\scalebox{0.7}[0.7]{\includegraphics[width=4cm]{co1y.ps}
\includegraphics[width=5cm]{co1z.ps}
\includegraphics[width=5cm]{co1xt.ps}}](img152.gif) [globally-modified data]
[globally-modified data]
![\scalebox{0.7}[0.7]{\includegraphics[width=4cm]{covs1y.ps}
\includegraphics[width=5cm]{covs1z.ps}
\includegraphics[width=5cm]{covs1xt.ps}}](img153.gif) [levels-modified data]
[levels-modified data]
![\scalebox{0.7}[0.7]{\includegraphics[width=4cm]{by6557.ps}
\includegraphics[width=5cm]{bz6557.ps}
\includegraphics[width=5cm]{bx6557.ps}}](img154.gif)