We seek a labelling
of an image, which is an
estimate of the true labelling
x*, according to the MAP
criterion,
(14)
From (14), we need to compute the prior probability of the
class and the likelihood probability of the observation. Since
x is considered as a realization of an MRF, its prior
probability can be derived from
(15)
It is also assumed that the pixel intensity yi follows a
Gaussian distribution with parameters
,
given the class label ,
(16)
Based on the conditional independence assumption of y
(8), we have the joint likelihood probability
which can be written as
(17)
with the likelihood energy
(18)
and the constant normalization term
.
It
is easy to show that
(19)
where
U(x|y) = U(y|x)+U(x)+const
(20)
is the posterior energy. The MAP estimation is equivalent
to minimizing the posterior energy function
(21)
Although mathematically simple, this type of MAP estimation
clearly presents a computationally infeasible problem. Therefore,
optimal solutions are usually computed using some iterative
optimization (minimization) techniques. In this paper, we adopt a
Iterated conditional modes (ICM) algorithm proposed by
Besag [2], which uses the ``greedy'' strategy in the
iterative local minimization and convergence is guaranteed after
only a few iterations. Given the data y and the other
labels
,
the algorithm sequentially
updates each xi(k) into
xi(k+1) by minimizing
,
the conditional
posterior probability, with respect to xi.
Next:Model Fitting Using the Up:MRF-MAP Classification Previous:MRF-MAP ClassificationYongyue Zhang 2000-05-11
![\begin{eqnarray*}P({\mathbf y\vert x})&=&\prod_{i\in \mathcal S}p(y_i\vert x_i)
...
...\mu_{x_i})^2}{2\sigma_{x_i}^2}
-\log(\sigma_{x_i})\Big)\bigg]
\end{eqnarray*}](img75.gif)
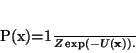
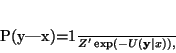
![\begin{displaymath}
U({\mathbf y\vert x})=\sum_{i\in \mathcal S}U(y_i\vert x_...
..._i-\mu_{x_i})^2}{2\sigma_{x_i}^2}
+\log(\sigma_{x_i})\Big],
\end{displaymath}](img77.gif)