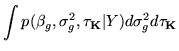Here we consider the full two-level model laid out in equations
2 and 3, applying the same ideas
as in the previous section to infer on the second-level
GLM height parameters ![]() . We will substitute into the
posterior for the full two-level model the summary result of the
first-level model derived in the previous section. This will
provide us with the way of inferring on the full two-level model
using just the summary result of the first-level, i.e. without
re-using the data
. We will substitute into the
posterior for the full two-level model the summary result of the
first-level model derived in the previous section. This will
provide us with the way of inferring on the full two-level model
using just the summary result of the first-level, i.e. without
re-using the data ![]() .
.
Considering equations 2 and 3.
The full joint posterior for the two-level model is:
A special case of equation 14 is when the
variances,
![]() on the
first-level GLM parameters are known with very high degrees of
freedom (
on the
first-level GLM parameters are known with very high degrees of
freedom (
![]() ). This is equivalent to
). This is equivalent to
![]() in equation 10 being a
Normal distribution instead of a t-distribution. In this case, the
prior distribution on
in equation 10 being a
Normal distribution instead of a t-distribution. In this case, the
prior distribution on
![]() reduces to a delta function
centered on
reduces to a delta function
centered on
![]() and the joint posterior
distribution on the second-level parameters reduces to:
and the joint posterior
distribution on the second-level parameters reduces to:
Equation 14 (or, in the special case,
equation 15) gives us the joint posterior
distributions of ![]() ,
,
![]() and
and
![]() .
However, as in the first-level model, we are actually interested
in inferring upon the marginal distribution over the GLM height
parameters,
.
However, as in the first-level model, we are actually interested
in inferring upon the marginal distribution over the GLM height
parameters, ![]() . This marginal posterior
. This marginal posterior
![]() cannot be obtained analytically. Therefore, we consider two
approaches, a fast posterior approximation and a slower but more
accurate approach using Markov Chain Monte Carlo (MCMC) sampling.
Crucially, in both approaches we are going to assume that
cannot be obtained analytically. Therefore, we consider two
approaches, a fast posterior approximation and a slower but more
accurate approach using Markov Chain Monte Carlo (MCMC) sampling.
Crucially, in both approaches we are going to assume that
![]() is a multivariate non-central t-distribution:
is a multivariate non-central t-distribution: